
Advancements in machine learning have revolutionized various domains, from text processing to image recognition. However, the robotics industry has not kept pace with the scaling of machine learning models, primarily due to the lack of large-scale datasets. In this regard, Google Robotics has introduced a new generalist model, PaLM-E, that uses transfer learning to overcome this limitation. In this blog post, we will discuss PaLM-E, its features, and how it is trained.
PaLM-E is an embodied multimodal language model developed by Google Robotics. It is designed to complement sensor data from a robotic agent with PaLM, a powerful large language model, to enable highly effective robot learning. The model can perform visual tasks such as describing images, detecting objects, or classifying scenes, and is also proficient in language tasks such as solving math equations or generating code.
PaLM-E works by injecting observations into a pre-trained language model. It transforms sensor data such as images into a representation that is comparable to how words of natural language are processed by a language model. This representation is then fed into the language model, which generates the output text. The inputs to PaLM-E are text and other modalities such as images, robot states, and scene embeddings in an arbitrary order. The output generated by PaLM-E could be an answer to a question or a sequence of decisions in text form.
The model architecture of PaLM-E consists of encoders that convert different inputs into the same space as the natural word token embeddings. These continuous inputs are mapped into something that resembles "words," although they do not necessarily form discrete sets. Since both the word and image embeddings now have the same dimensionality, they can be fed into the language model. PaLM-E is initialized for training with pre-trained models for both the language (PaLM) and vision components (Vision Transformer, a.k.a. ViT). All parameters of the model can be updated during training.
PaLM-E is designed to address a large set of robotics, vision, and language tasks simultaneously without performance degradation compared to training individual models on individual tasks. It enables PaLM-E to learn robotics tasks efficiently in terms of the number of examples it requires to solve a task. PaLM-E attains significant positive knowledge transfer from both the vision and language domains, improving the effectiveness of robot learning.
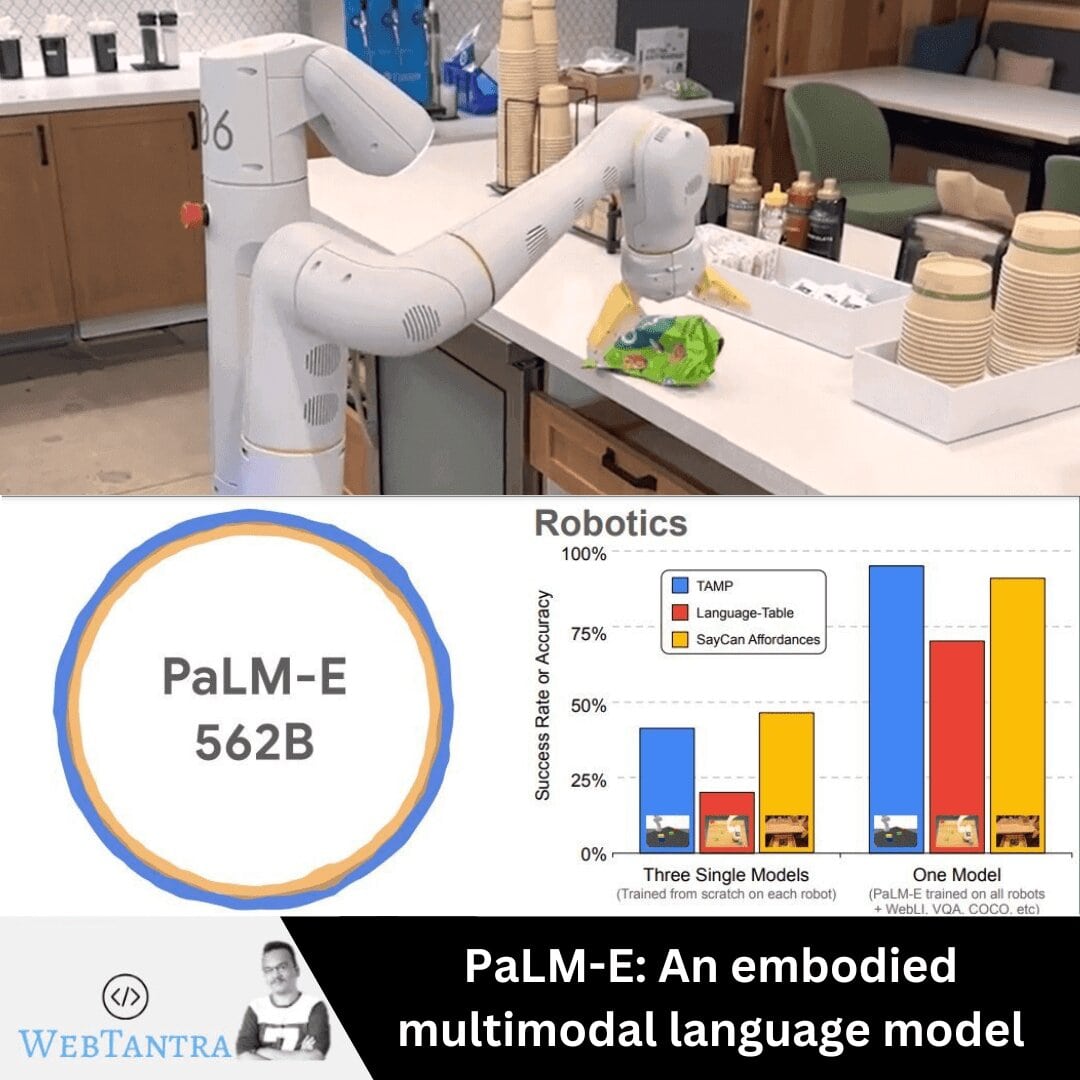
PaLM-E has been evaluated on three robotic environments, two of which involve real robots, as well as general vision-language tasks such as visual question answering (VQA), image captioning, and general language tasks. The model has shown promising results in making decisions on robots and has paired well with low-level language-to-action policy to translate its output text into actions. PaLM-E-562B, the largest instantiation of PaLM-E, sets a new state of the art on the visual-language OK-VQA benchmark, without task-specific fine-tuning, while maintaining excellent language-only task capabilities.
PaLM-E is a significant development in the field of robotics and machine learning. Its multimodal approach and positive knowledge transfer enable it to address various tasks simultaneously and efficiently. PaLM-E has the potential to revolutionize the robotics industry by improving robot learning and enabling more advanced robotics applications.